



The goal of creating RAKE was to develop a method for extracting highly effective keywords, works on individual documents to enable the application to dynamic collections, is easily adaptable to new domains, and works well on a variety of document types, especially those that don’t adhere to strict grammar conventions.

RAKE is based on the observation that keywords typically have numerous words but infrequently have stop words or standard punctuation, like the function words and, the, and of, or other words with little lexical meaning. This justification is based on the assumption that such phrases are used far too frequently and widely to be helpful to users during analysis or search operations.
In the first step, RAKE breaks down a document’s content into a list of candidate keywords before starting to extract keywords from it. The document’s text is initially divided into an array of words using the designated word delimiters. Then, phrase delimiters and stop words are used to separate this array into groups of related words. A candidate keyword is a group of words that are assigned the same place in a textual sequence.

The next step will be the keyword scores. A score is computed for each candidate keyword and is defined as the sum of its member word scores when each candidate keyword has been found, and the graph of word co-occurrences illustrated. Based on the degree and frequency of the word vertices in the graph, we assessed three metrics for generating word scores: (1) word frequency (freq(w)), (2) word degree (deg(w)), and (3) ratio of the degree to frequency (deg(w)/freq(w)).
The following step will be adjoining keywords. Extracted keywords do not contain inner stop words since RAKE divides candidate keywords by stop words. While the ability of RAKE to identify particular terminology has attracted much attention, there has also been engagement in finding keywords that contain interior stop words like “axis of evil.” To find these, RAKE searches for keyword pairs that are adjacent to one another at least twice in the same document and in the same order. Then, those keywords and their inside stop words are combined to form a new candidate keyword. The new keyword’s score is calculated by adding the scores of its constituent keywords.

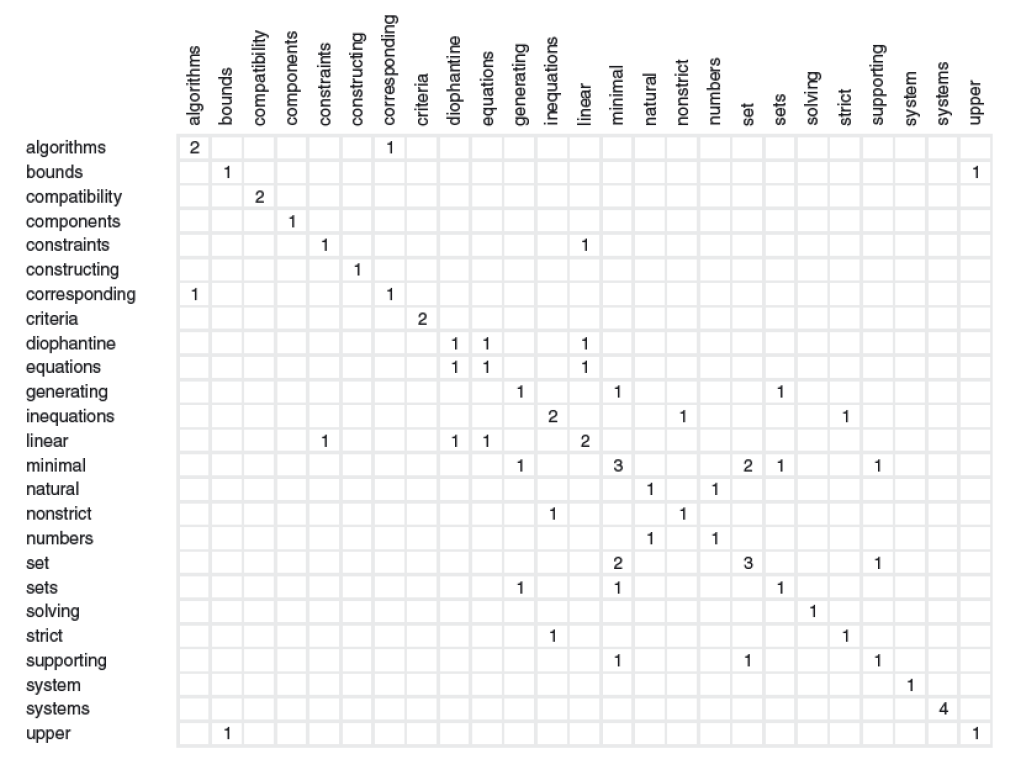
The final step will be to extract keywords. The top T-scoring candidates are chosen as the document’s keywords after candidate keywords are scored. T is calculated as being equal to one-third of the words in the graph. 28 content words totalling T = 9 keywords make up the sample abstract. Figure 13 compares the human-given keywords to the sample abstract with the keywords recovered by RAKE. We employ the statistical measurements of precision, recall, and F-measure to assess RAKE’s accuracy. Six of the nine retrieved keywords are true positives, meaning that they precisely match six of the manually assigned keywords. Natural numbers are a miss for the benchmark evaluation, even if similar to the supplied keyword set of natural numbers. As a result, the list of retrieved keywords contains three false positives, giving it a precision of 67%. A recall of 86% is obtained by comparing the seven manually assigned keywords with the six true positives found in the collection of extracted keywords. An F-measure of 75% results from giving precision and recall equal weights.